「この馬が買いです」と言う競馬AIに、「なぜ?」 と聞いたら、答えは返ってくるでしょうか。
多くのAIは、ここで黙り込みます。高い精度をうたっていても、いざ「その予測の根拠を説明して」と求められると、何も語れない。これがいわゆる 「ブラックボックス問題」 です。
当たるか当たらないか、と同じくらい大事なのが、「なぜそう予測したのかを説明できるか」だと私は考えています。説明できないAIは、間違ったときに検証もできないからです。
なぜ「ブラックボックス」が問題なのか
近年の競馬AIの多くは、勾配ブースティング (LightGBM / XGBoost) やニューラルネットといった、高精度だが内部が複雑なモデルを使っています。これらは予測精度が高い反面、「なぜその出力になったか」が人間には直感的にわかりません。
精度さえ高ければ中身はわからなくてもいい、という考え方もあります。しかし競馬AIでは、ブラックボックスのまま運用することに、次のような実害があります。
- 信頼できない: 根拠が説明できない予測を、お金を賭けて信じられるか
- 検証できない: 外れたとき「何が原因だったのか」を切り分けられない
- 過学習に気づけない: モデルが"おかしな特徴量"に依存していても発見できない
そこで登場するのが、「予測の根拠を後から説明する」ための手法群です。その中で、現在もっとも広く使われているのが SHAP です。
SHAP値とは何か
SHAP (SHapley Additive exPlanations) は、2017年に提案された、機械学習モデルの予測を説明するための手法です。その理論的な土台は、ゲーム理論の「シャープレイ値」にあります。
競馬AIに当てはめると、こうなります。1頭の馬の予測スコア (たとえば「勝率15%」) は、いきなり15%になるわけではありません。全馬の平均的な予測値からスタートして、その馬が持つ各特徴量が、スコアを上げたり下げたりした結果として15%にたどり着きます。
「なぜこの予測になったか」を1頭分解してみる
言葉だけでは伝わりにくいので、架空の1頭を使って分解してみます。ここでは説明のために、誰もが知っている公知の要素(枠順・斤量・休養明け・前走着順など)だけを使います。
あるレースの全馬の平均勝率が 10% だったとします。そこから、ある1頭「ステラ号 (仮)」の予測勝率が 18% に決まるまでを、SHAP値で分解すると次のようになります。
- (出発点) 全馬の平均 → +10.0%
- 前走着順 = 1着 → +6.0%(押し上げ)
- 距離適性 = 得意距離 → +3.0%(押し上げ)
- 枠順 = 2枠 (内目) → +2.5%(押し上げ)
- 斤量 = 57kg (重め) → −2.5%(押し下げ)
- 休養明け = 3ヶ月ぶり → −1.0%(押し下げ)
- 合計 = 予測勝率 → 18.0%
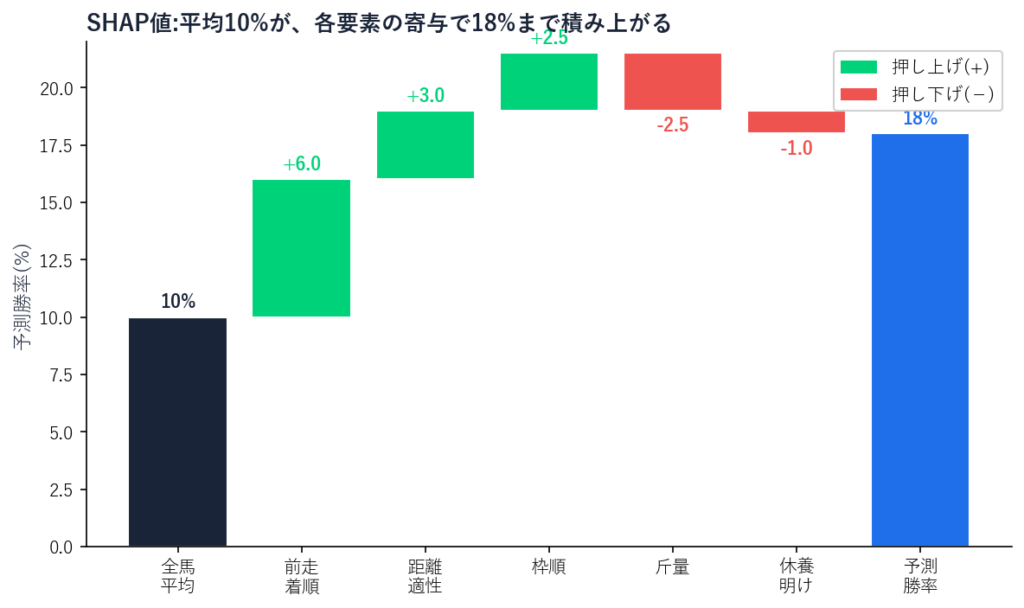
この表を読むと、ステラ号の予測勝率18%が「どう積み上がったか」が一目でわかります。「前走1着」と「距離適性」が大きく勝率を押し上げ、一方で「重い斤量」と「久々の休養明け」がブレーキになっている、という具合です。
※ 上記の数値・要素はすべて、説明のための架空の例です。当サイトの現役モデルが実際に使っている特徴量とは関係ありません (この点は後半で改めて触れます)。
SHAPでわかる「競馬の本質」
SHAPは、1頭ごとの説明だけでなく、何千頭・何万走分のSHAP値を集計することで、モデル全体 ―― ひいては競馬というゲームそのものの傾向を浮かび上がらせます。
たとえば、SHAP値を大量に集計すると、次のような「肌感覚として知られていたこと」が数字で裏づけられます。
- 距離適性の寄与は、距離が延びるほど大きくなる傾向 (短距離は紛れが多く、長距離は適性が出やすい)
- 枠順の寄与は、コース形態によって符号が反転する (内枠有利のコースと外枠有利のコースがある)
- 斤量の寄与は一律ではなく、馬齢や馬体重との組み合わせで効き方が変わる
モデルの「健康診断」にも使える
SHAPは予測の道具であると同時に、「競馬というゲームの構造を読み解くレンズ」でもある。これが、この記事のタイトルにある「競馬の本質」の意味です。
SHAPの限界・誤解
ここまで読むと万能の道具のように思えるかもしれませんが、SHAPにも明確な限界があります。誤解されやすいポイントを正直に書いておきます。
誤解 1: SHAP値は「因果」ではない
もっとも重要な注意点です。SHAP値が示すのは、あくまで「モデルがその特徴量をどう使ったか」であって、「現実世界での因果関係」ではありません。
「前走着順のSHAP値が大きい」は、「前走で勝てば次も勝ちやすくなる (因果)」を意味しません。前走の好走と今走の好走は、どちらも「その馬の地力が高い」という共通の原因の結果かもしれない。SHAPは相関的な寄与を分解しているだけで、因果の矢印までは教えてくれません。
誤解 2: 相関する特徴量どうしで寄与が割れる
似た情報を持つ特徴量が複数あると (たとえば「前走着順」と「前走タイム」)、本来1つにまとまるはずの寄与が、両者に分散して配分されます。結果として、個々の特徴量のSHAP値が実際の重要性より小さく見えることがあります。
誤解 3: 「説明できる」と「予測が正しい」は別
SHAPは「モデルがなぜそう予測したか」を説明する道具であって、その予測が当たるかどうかは保証しません。間違ったモデルの間違った予測も、SHAPはもっともらしく説明してしまいます。
見せられること、見せられないこと
ここで、正直なジレンマをお話しします。
SHAPは強力です。あまりに強力なので、現役モデルのSHAP分析をすべて公開してしまうと、どの特徴量がどう効いているかが丸わかりになり、同じモデルが誰にでも再現できてしまいます。研究の独自性、ひいてはこのサイトの存在意義が消えてしまう。
だからこそ、当サイトでは公開のラインをはっきり分けています。
| 公開するもの | 公開しないもの |
|---|---|
| SHAPという手法そのもの・考え方 | 現役モデルの核心特徴量の名前・組み合わせ |
| 検証プロセス・モデルの精度と限界 | 特徴量ごとの正確な重要度ランキング |
| 公知の要素を使った説明デモ | 独自に設計した特徴量の生成ロジック |
| うまくいかなかった実験・失敗ログ | 現役モデルがまだ使っている要素の詳細 |
"理由を説明できるAI"を目指して
ここまで読んでいただいて、ありがとうございました。
予想屋は、「当たった」「外れた」しか語りません。当たれば自慢し、外れれば次のレースの話にすり替える。そこに「なぜそう予測したのか」という検証はありません。
当たることと、説明できること。その両方を追いかけるのが、予想屋ではなく研究者としてのスタンスだと考えています。SHAPは、その「説明できる」を支える、もっとも信頼できる相棒の一つです。
何度でも繰り返しますが、どんなに説明がもっともらしくても、それは過去データから推定された確率的な分析にすぎません。馬券・出資の最終判断は、必ずあなた自身の責任で行ってください。
関連記事
当サイトの他の研究記事も、よろしければお読みください。