私が初めて競馬AIを作った時、バックテストで単勝回収率 200% という派手な数字が出ました。
しかし実戦運用すると、3ヶ月で 50%まで落ち込みました。
原因はモデルそのものではなく、「検証方法」の根本的な誤りでした。
この記事では、競馬AIにおいて時系列CV (クロスバリデーション) がなぜ必須なのか、どう実装すべきか、私の運用モデルでの実例を交えて解説します。
通常のクロスバリデーション (KFold) の問題点
KFoldの基本おさらい
通常使われる「KFold交差検証」は、データを5分割して、4セットで学習・1セットで検証することを5回繰り返す方法です。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_idx, test_idx in kf.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
# 学習と評価シンプルで使いやすく、Kaggleの入門記事でもよく見ます。
競馬データで起こる「時系列リーケージ」
しかし競馬データで KFold を使うと、致命的な問題が起こります。
なぜダメか? 実戦で考えてみてください。2023年のレースを予測する時、2024年のデータは存在しません。
KFold は「ランダム分割」なので、時系列を完全に無視します。これが 「時系列リーケージ」 と呼ばれる現象です。
時系列リーケージが起こると、検証時には「未来情報を使って過去を予測」できるため、不当に高い精度が出ます。これがバックテスト200%の正体です。
実戦では未来情報は使えないので、当然精度は落ちます。私の場合は 3ヶ月で半分以下 になりました。
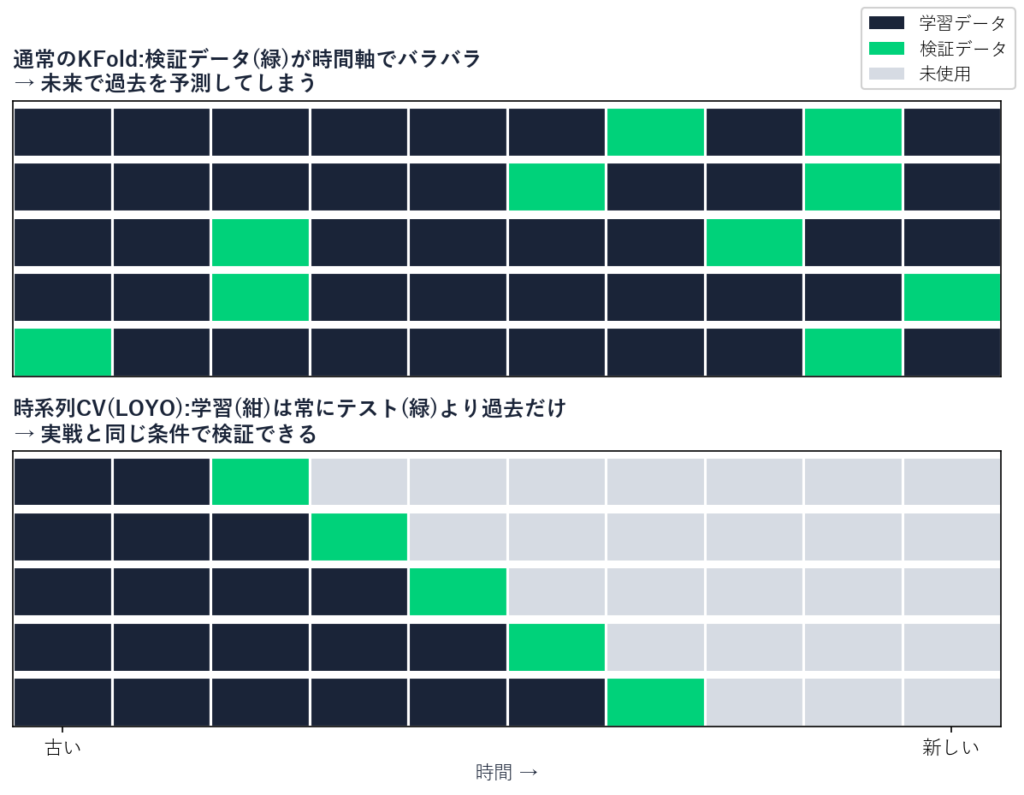
時系列CVの基本
TimeSeriesSplit の仕組み
scikit-learn には TimeSeriesSplit という時系列向けのCVが用意されています。
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5)
for train_idx, test_idx in tscv.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
# 学習と評価Walk-Forward と Expanding Window の違い
時系列CVには2つのスタイルがあります。
- Expanding Window: 学習データを累積していく (初期 → 全期間)。TimeSeriesSplit のデフォルト
- Sliding Window: 学習データの長さを固定して、ウィンドウを移動させる
競馬では Expanding Window が一般的 です。古いデータも含めて学習することで、レアな現象 (重い馬場、大荒れレース) を含む頑健なモデルになります。
競馬で推奨する LOYO (Leave-One-Year-Out) 設計
なぜ年単位で分けるべきか
私が推奨するのは、競馬特有の事情を考慮した 「LOYO (Leave-One-Year-Out)」設計 です。理由は3つあります。
理由1: 競馬の季節性
春G1 (4-6月)、秋G1 (10-11月)、有馬記念 (12月)、と1年で1サイクルです。月単位で分けると同じ年内で「春→秋を予測」となり、季節バイアスを正しく評価できません。
理由2: トレンドシフト
馬場改修、騎手騎乗依頼の変化、人気馬の世代交代など、年をまたぐと予測の難易度が変わります。年単位で分けることで「全く新しい1年」をどう予測できるかを評価できます。
理由3: 異常年の影響を分離
特定の年にだけ起こった珍事 (雨続き、特定種牡馬のブレイクなど) が他年に漏れません。
LOYO の実装
import lightgbm as lgb
from scipy.stats import spearmanr
def leave_one_year_out_cv(df, target_col, year_col='year', min_train_years=3):
"""
競馬データ向け年単位クロスバリデーション(LOYO)
Args:
df: 全データ(年カラム必須)
target_col: 目的変数のカラム名
year_col: 年のカラム名
min_train_years: 学習データの最低年数
Returns:
results: 各年の検証結果リスト
"""
years = sorted(df[year_col].unique())
results = []
# 最初の3年は学習データとして確保
for test_year in years[min_train_years:]:
train_years = [y for y in years if y < test_year]
train = df[df[year_col].isin(train_years)]
test = df[df[year_col] == test_year]
X_train = train.drop([target_col, year_col], axis=1)
y_train = train[target_col]
X_test = test.drop([target_col, year_col], axis=1)
y_test = test[target_col]
model = lgb.LGBMRegressor(random_state=42)
model.fit(X_train, y_train)
pred = model.predict(X_test)
spearman, _ = spearmanr(y_test, pred)
results.append({
'test_year': test_year,
'train_size': len(train),
'test_size': len(test),
'spearman': spearman,
})
return resultsこれだけで「未来で過去を予測する」事故は防げます。
私の血統評価AIでの実装事例
14年分の LOYO 検証結果
私が運用している「血統評価AI」(全JRA 122,327頭 を血統情報のみで予測) では、14年分のLOYO検証 を採用しています。
主軸指標「log_honsho_man (対数本賞金)」の Spearman 相関は、0.372 ± 0.021(14年平均±標準偏差)です。
地味な数字に見えるかもしれません。しかし「最弱年」の精度を重視する設計にしているため、この 標準偏差0.021というブレの小ささ は私にとって最も大事な指標です。
なぜ「最弱年」を重視するのか
平均値だけ見ていると、たまたま当たり年があった時に過大評価しがちです。
例えば、2つのモデルを比べてみます。
- モデルX: 平均 0.4 / 標準偏差 0.10 → 最弱年は 0.30 程度
- モデルY: 平均 0.37 / 標準偏差 0.02 → 最弱年でも 0.35 程度
どちらが実戦で安心か? 私は 後者 だと考えています。
失敗から学んだ落とし穴
時系列CVを採用しても、別の形でリーケージが起こることがあります。私が過去にロールバックした実験を3つ紹介します。
修正コード:
# NG例(リーケージあり)
sire_stats = df.groupby('sire_name')['honsho'].sum()
# OK例(target_year以前のみ)
def cutoff_stats(df, target_year):
past = df[df['year'] < target_year]
return past.groupby('sire_name')['honsho'].sum()実務的なチェックリスト
時系列CVを設計するときの確認事項です。これだけ守れば、バックテスト200%の幻に騙されることは無くなります。
- 検証期間より前のデータだけで特徴量を計算しているか
- 累計統計が
target_year - 1でカットオフされているか - target horse 自身の戦績が特徴量に混入していないか
- cross系特徴量で自己除外を実装しているか
- 季節性・トレンドシフトを意識した分割になっているか
- 平均値だけでなく、最弱年の精度・標準偏差も見ているか
- 「不利な数字」を隠さず記録しているか
まとめ
時系列クロスバリデーションは、競馬AIにおける最低限の 基礎工事 です。派手なバックテスト結果より、「最弱年でも安定する精度」を信じる。
私の血統評価AIも、Spearman 0.372 という地味な数字ですが、14年間ブレの小さい数字を信じて運用しています。派手な数字に惑わされない検証設計こそが、長く続けられる研究者の条件だと思っています。
参考: 私の運用モデル
本記事で言及した数字は、すべて私が運用している以下のモデルから引用しています。
モデルの月次精度レポートを無料で公開しています。よろしければ下記からフォローをお願いします。